












怎么解决DeepSeek服务器繁忙崩溃问题
1. 使用网络加速器
网络加速器可以优化网络连接,减少延迟,提高访问速度。例如,使用迅游加速器为DeepSeek加速,能为您分配最优的网络节点,确保顺畅连接到服务器,从而解决访问问题。
2. 清理缓存和数据
长时间使用DeepSeek后,缓存和数据可能会积累,导致软件运行缓慢或出现崩溃。清理DeepSeek的缓存和数据可以释放存储空间并提升性能。在手机的设置中找到应用管理,选中DeepSeek进行清理即可。
3. 错峰使用
避开高峰时段(如工作时间或晚上高峰),选择在清晨或深夜等用户较少的时间段使用DeepSeek服务,可以减少遇到服务器繁忙的情况。
4. 使用第三方平台
如果DeepSeek官方服务器繁忙,您可以尝试访问支持DeepSeek模型的第三方平台,如硅基流动、纳米AI搜索、秘塔AI搜索等。
我们重点介绍一下 硅基流动 提供的第三方平台:
硅基流动+Chatbox AI组合方案
整个步骤非常简单,最多5分钟就能搞定。
1、注册硅基流动,获取API key
首先,简单介绍一下,SiliconCloud - 硅基流动是一个国产大模型云服务平台,由团队硅基流动(SiliconFlow)推出,致力于提供高效能、低成本的多品类 AI 模型服务(MaaS),是 AI 应用的基础设施平台。
汇聚了众多主流大模型,如阿里旗下的通义大模型 Qwen2、智谱旗下的 GLM-4、幻方量化旗下的 DeepSeek V2 系列,DeepSeek -V3、DeepSeek -R1,为用户提供了多样化的选择。
访问官网:https://cloud.siliconflow.cn/

登陆之后,直接就进入【模型广场】了。排在第一位的模型就是DeepSeek -R1。


这里先不用管,直接选择左边的导航栏,找到【API密钥】,点进去,再点右上角的新建API密钥。


密钥描述这块可以随便写,且可以建多个密钥。

新建完成之后,你就会得到一个加密的API Key了,鼠标轻轻的放在这串带星号的上面,轻轻的点击一下复制。至此,你的API key就到手了,第一步就算大功告成了。

2、Chatbox AI下载与配置
Chatbox AI 是一款功能强大的 AI 客户端应用和智能助手,支持 Windows、MacOS、Android、iOS、Linux 和网页版。
访问地址:https://chatboxai.app/zh#download


你可以直接下载你需要的客户端,下载后,傻瓜式安装即可。
安装完成之后,首次打开,会弹出下述提示框,选择”使用自己的API Key或本地模型“选项

若非首次打开,可以直接点击左下角的设置。接着,在模型提供方下拉列表中,找到这个SiliconFlow API,这个就是硅基流动的英文名。
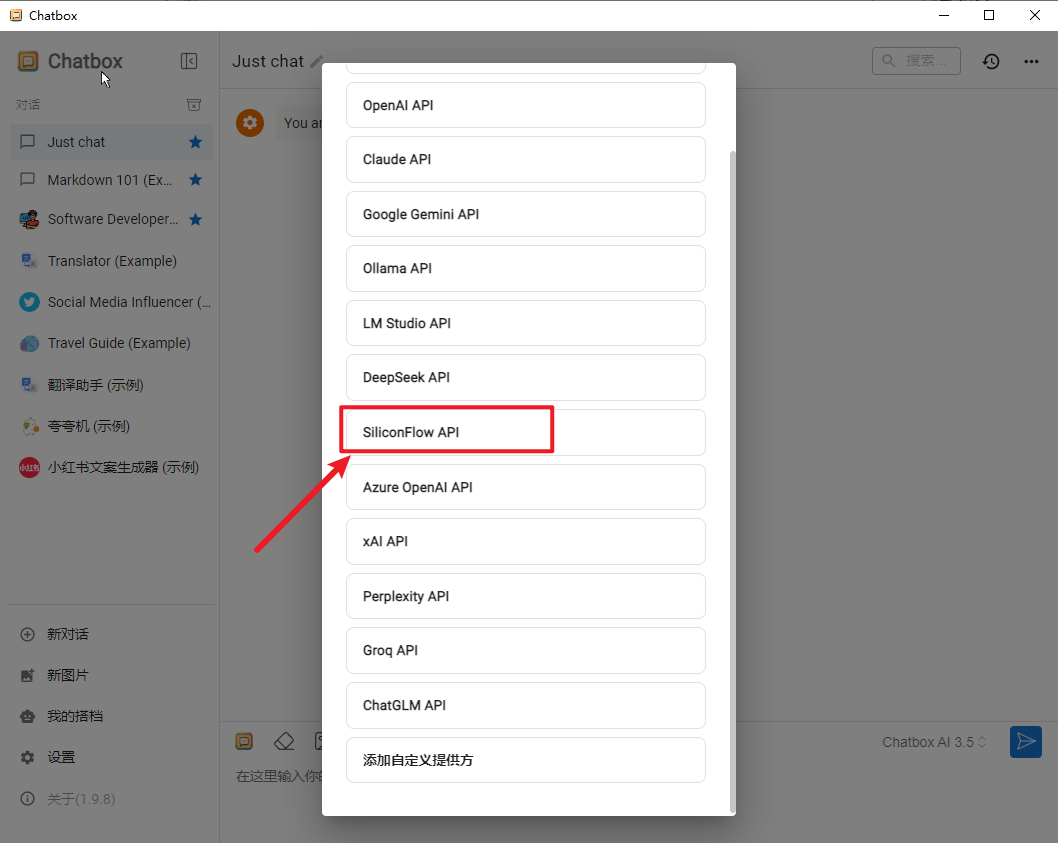

直接黏贴第一步中的 API 秘钥, 然后选择 DeepSeek R1模型:
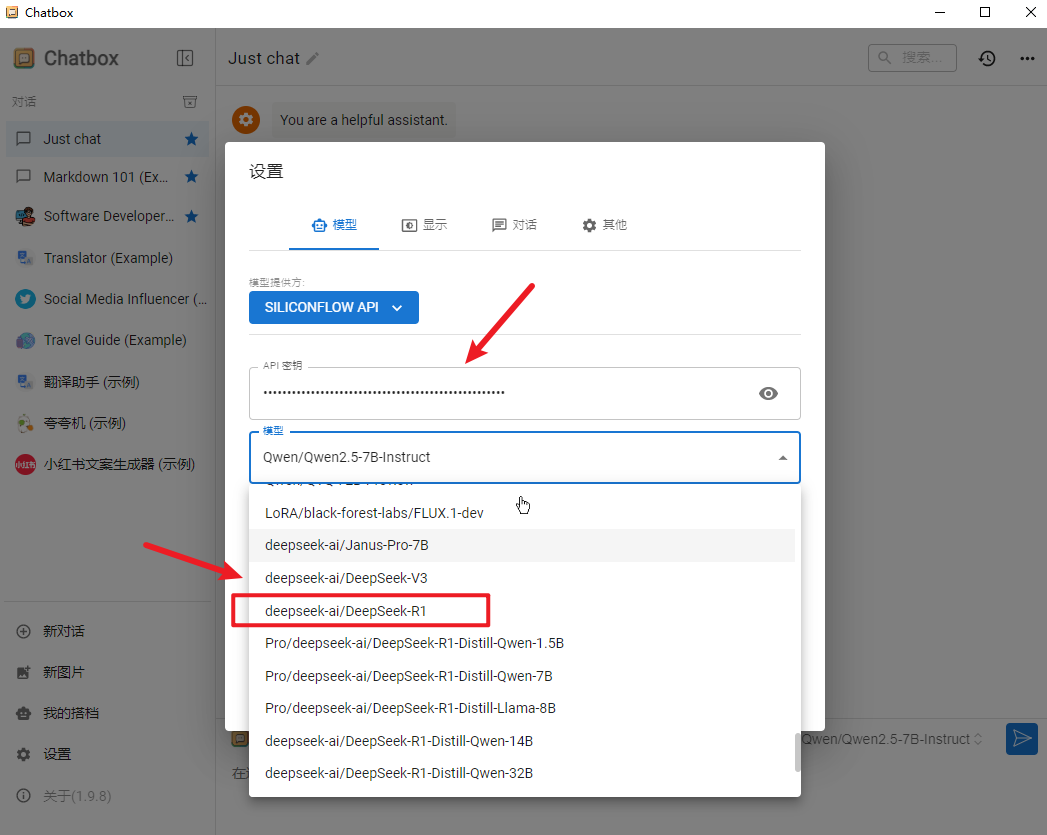

然后点击一下保存,就完事了。

最后,在下方对话框左下角就可以看到我们当前的模型,来测试下,比如我问:"Ergonomic Chairs vs Traditional Chairs: Which Saves Your Spine? 模拟国外专业编辑人员,生成一篇利于google seo的博文,字体在2500单词左右 "
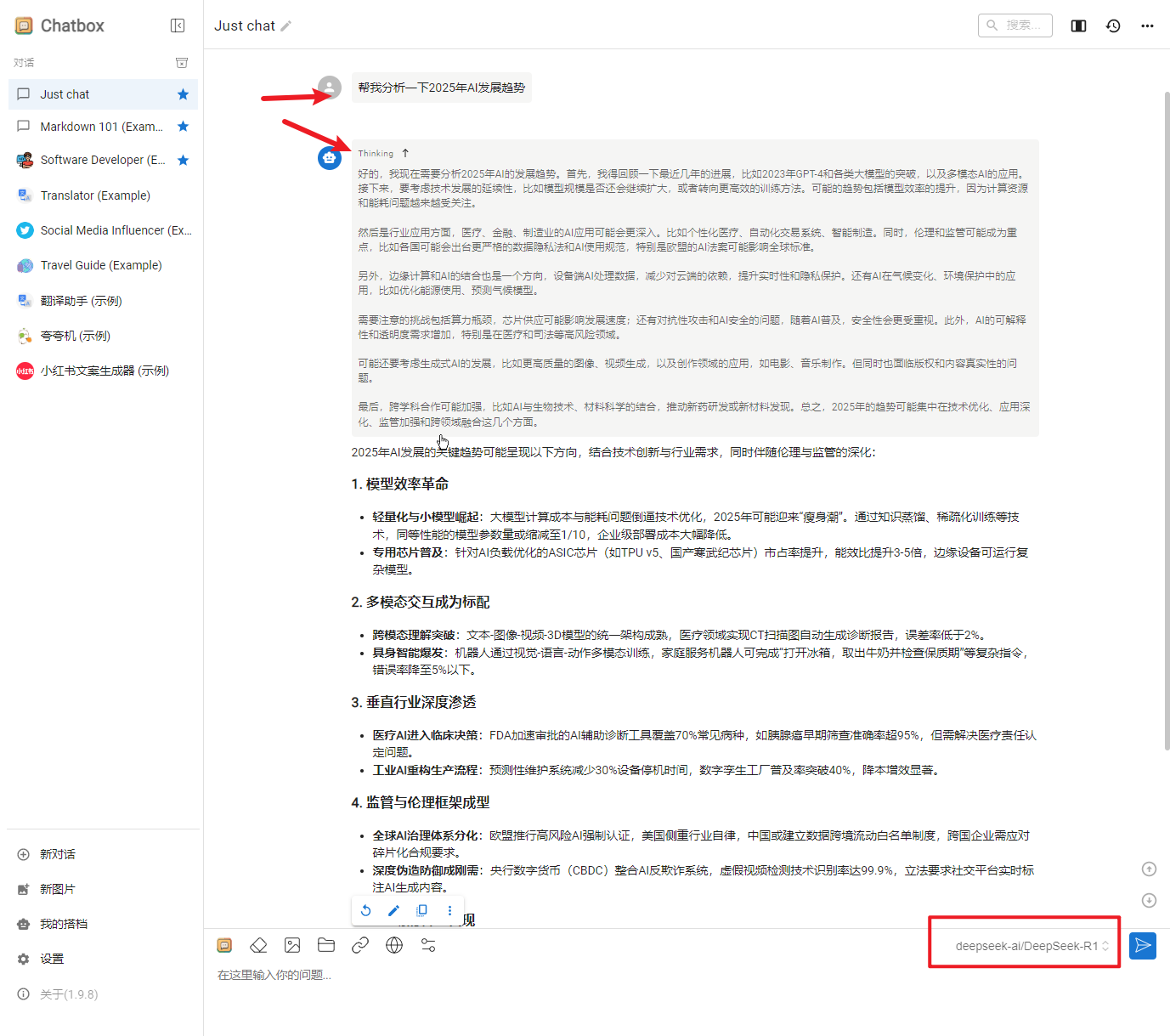

速度快,效果相当可以。而且最难能可贵的是,ChatBox AI的界面,是带有思考过程的。。。
至此,你就拥有了一个你专属的DeepSeek。
5. 本地部署
对于有技术能力的用户,可以考虑在本地部署DeepSeek模型。这可以避免服务器繁忙的问题,并提供更稳定的使用体验。一些教程提供了详细的本地部署步骤,供您参考。
以下是 DeepSeek 不同版本模型的硬件要求,小伙伴们可以结合自己电脑配置选择版本
| 模型版本 | 参数量 | 显存需求(FP16) | 推荐 GPU(单卡) | 多卡支持 | 量化支持 | 适用场景 |
|---|---|---|---|---|---|---|
| DeepSeek-R1-1.5B | 15亿 | 3GB | GTX 1650(4GB显存) | 无需 | 支持 | 低资源设备部署(树莓派、旧款笔记本)、实时文本生成、嵌入式系统 |
| DeepSeek-R1-7B | 70亿 | 14GB | RTX 3070/4060(8GB显存) | 可选 | 支持 | 中等复杂度任务(文本摘要、翻译)、轻量级多轮对话系统 |
| DeepSeek-R1-8B | 80亿 | 16GB | RTX 4070(12GB显存) | 可选 | 支持 | 需更高精度的轻量级任务(代码生成、逻辑推理) |
| DeepSeek-R1-14B | 140亿 | 32GB | RTX 4090/A5000(16GB显存) | 推荐 | 支持 | 企业级复杂任务(合同分析、报告生成)、长文本理解与生成 |
| DeepSeek-R1-32B | 320亿 | 64GB | A100 40GB(24GB显存) | 推荐 | 支持 | 高精度专业领域任务(医疗/法律咨询)、多模态任务预处理 |
| DeepSeek-R1-70B | 700亿 | 140GB | 2x A100 80GB/4x RTX 4090(多卡并行) | 必需 | 支持 | 科研机构/大型企业(金融预测、大规模数据分析)、高复杂度生成任务 |
| DeepSeek-671B | 6710亿 | 512GB+(单卡显存需求极高,通常需要多节点分布式训练) | 8x A100/H100(服务器集群) | 必需 | 支持 | 国家级/超大规模 AI 研究(气候建模、基因组分析)、通用人工智能(AGI)探索 |
值得注意的是本地电脑私有化部署,从方法技术上是可行的,有电脑就可以部署,但我想说的是,DeepSeek R1的模型参数是671B,差不多至少需要1000个G以上的显存,你才能跑得动满血版本。你别信那些说本地部署有多牛叉,光所需显卡配置这一项要求 ,就不是一般普通玩家能玩的起的。而若采用蒸馏版模型比如1.5b,虽然一般电脑配置就可以跑起来,但和官方 671B 满血版模型参数,性能和效果差了十万八千里,本地部署满血版本的对硬件要求非常高,一般人真的是吃不消的,所以参考一下第三方平台的。